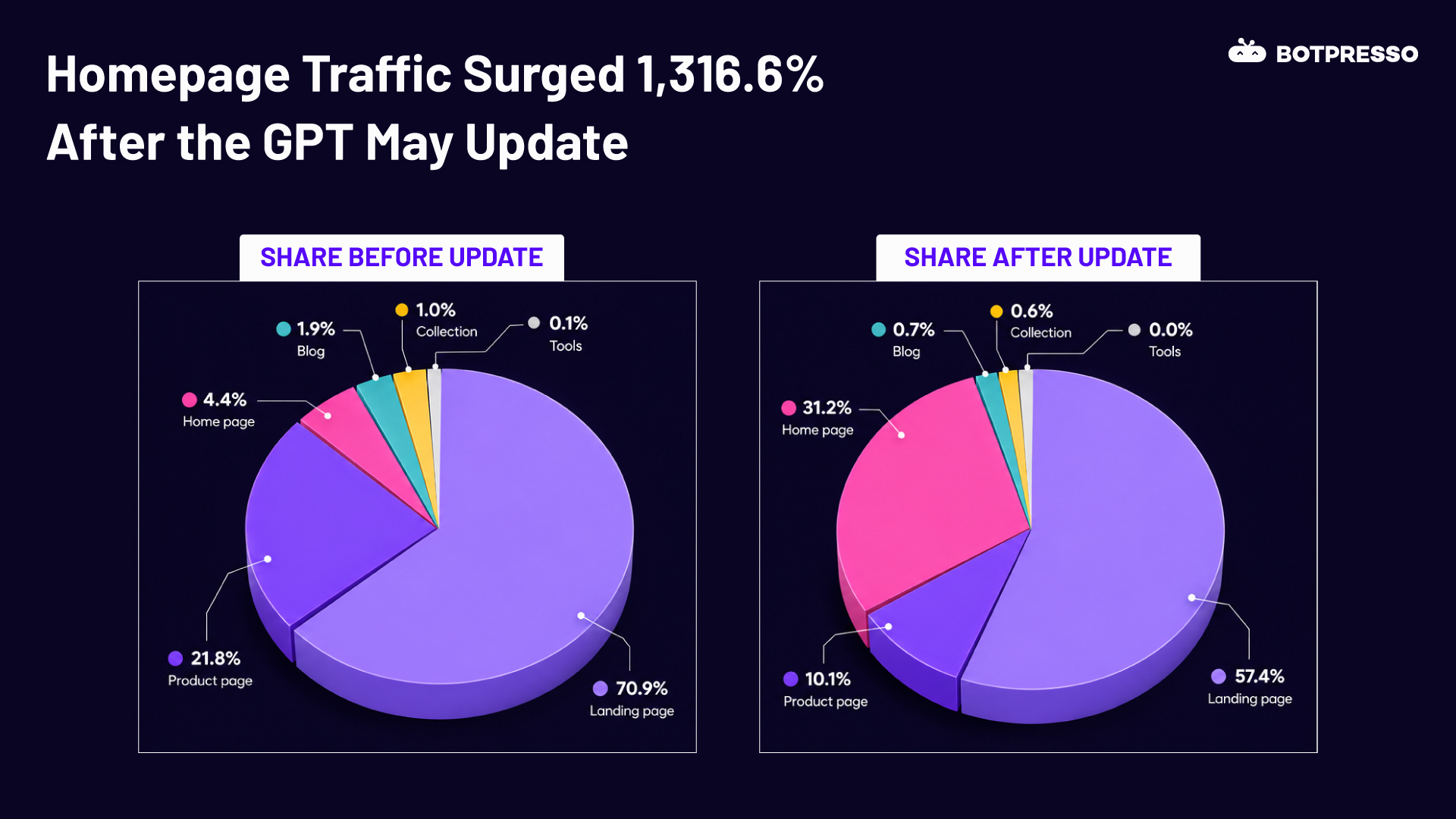
Ever conducted content pruning for a large website with thousands or millions of pages? The intimidation of making the decision can make you nervous. Trust me we have all been there.

Today, I am sharing a Python script that will tell you if the URL has any keyword ranking in the top 20, which is that keyword & its search volume.
Why is this helpful?
It is helpful because you wouldn’t want to prune a page that was ranking at 18th position & on its way to crawl the SERP ladder to make it to page 1 of Google.
What do you need?
There is a caveat for making the use of this Python Script. It is important that you have already mapped all the keywords to the URL & already added it to your keyword rank tracking tool.
An ideal keyword rank tracking tool will tell you which keyword ranks at which position with what URL and the keyword’s search volume. We here at Botpresso religiously make use of the Semrush position tracker.
What you need from the rank tracking tool is an export containing the following columns, keyword, search_volume, position, and ranking_url
You have to upload this CSV to your Python IDE whether it is Replit or Google Colab and then you have to specify the file path in the Python Script and just run the script. Ta-da! You have it, you will get an export CSV containing the following columns. ranking_url’, ‘best_ranking’, ‘highest_ranking_keyword’, ‘search_volume
Here in the best_ranking column, you will get the ranking position number, the remaining column names are self-explanatory.
Without further ado, here is the Python Script.
import pandas as pd
# Function to process the uploaded CSV file
def process_csv(input_file, output_file):
try:
# Reading the uploaded CSV file
data = pd.read_csv(input_file)
# Checking for required columns
required_columns = ['keyword', 'search_volume', 'position', 'ranking_url']
if not all(col in data.columns for col in required_columns):
print("Error: CSV file doesn't contain all required columns.")
return
# Converting 'position' column to numeric values
data['position'] = pd.to_numeric(data['position'], errors='coerce')
# Filtering URLs with at least one keyword in top 10
top_10_urls = data[data['position'] <= 19]['ranking_url'].unique()
# List to store results
results = []
for url in top_10_urls:
url_data = data[data['ranking_url'] == url]
top_keyword = url_data[url_data['position'] <= 19].nlargest(1, 'search_volume')
if not top_keyword.empty:
best_ranking = top_keyword.iloc[0]['position']
highest_ranking_keyword = top_keyword.iloc[0]['keyword']
search_volume = top_keyword.iloc[0]['search_volume']
results.append({'ranking_url': url, 'best_ranking': best_ranking,
'highest_ranking_keyword': highest_ranking_keyword,
'search_volume': search_volume})
# Creating DataFrame from the results list
result_df = pd.DataFrame(results, columns=['ranking_url', 'best_ranking', 'highest_ranking_keyword', 'search_volume'])
# Writing results to a new CSV file
result_df.to_csv(output_file, index=False)
print(f"Exported data to '{output_file}' successfully.")
except Exception as e:
print(f"An error occurred: {str(e)}")
# Replace 'import_file_path.csv' and 'output.csv' with your file names
process_csv('your_file_path.csv', 'output.csv')
Based on the output of the Python Script you can do a VLOOKUP & update next to the URL, status whether it has any keyword in the Top 20 or not.
In the below screenshot of Google Spreadsheet, you can see how I have done URL Retention/killing validation in 3 layers.
- GSC Clicks if more than 0 then retain it (but what if clicks are ZERO but the URL indeed ranks for some keyword in the top 20)
- If the URL has any keyword that ranks in the Top 20 then retain it
![]()
Based on these criteria we make it certain that we don’t end up killing a page that would crawl the SERP ladder but we interrupted the progress by looking just at the click number and completely turned a blind eye to keyword rankings.
This Python Script helps you expedite the content-pruning decision process. Stay tuned for more Python Scripts we are brewing for faster SEO Processes.