
3. Only 55.3% of URLs were 200 Status Code Pages
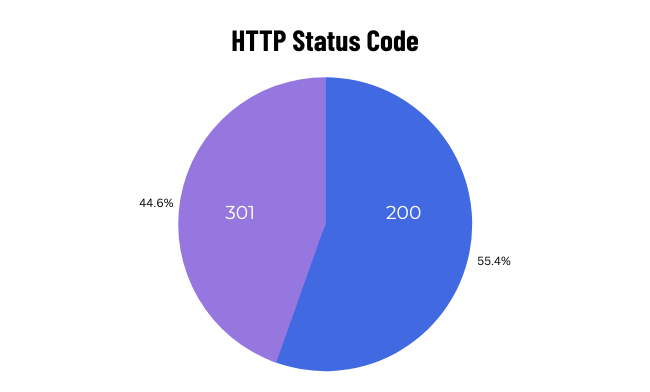
This was a massive issue.
It explains the amount of non-indexable internal linking that had taken place on the website.
HTTP Status code that SE bots come across while crawling impacts the experience with a site. On a very basic level, the 3 popular HTTP Status Codes are:
2XX – The page is working and is available on the destination where it is hosted
3XX – The page’s Location is changed either permanently or temporarily
4XX – 404 Status code means that the page is broken.
Ideally, SE bots would have a good experience if most of their precious time is spent crawling the 200 status code pages that carry content valuable to the users.
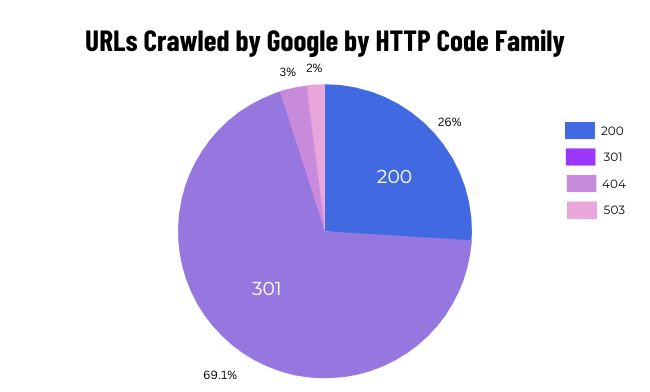
To quantify 18.8K 3XX status code pages were receiving 57.8K internal links.
This was a massive waste of Google Bot’s crawl budget.
In fact, 69.4% of the pages that Google Bot crawled were actually non-indexable and this says a thing or two about how G bot perceives the quality of our website.
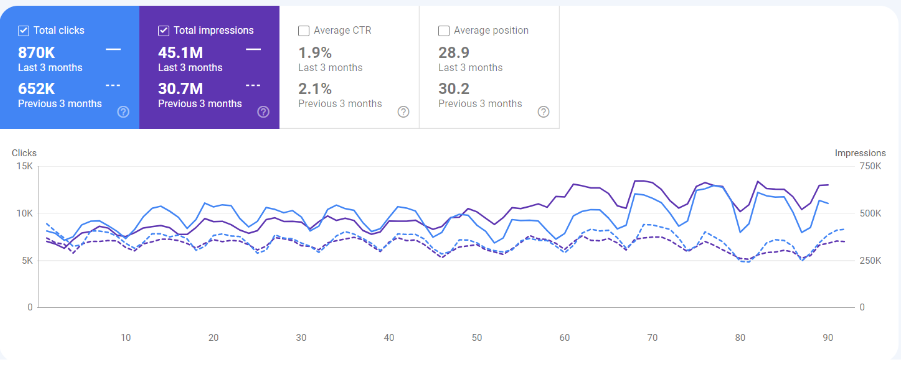
After getting the issue fixed, we did see a visible improvement in the number of crawl requests received from Google Bot every day.
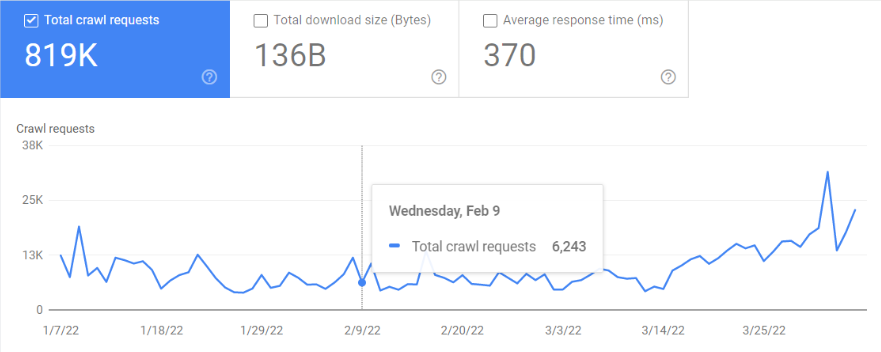
We also observed a massive increase in the number of indexed pages.

4. Crawl depth of >40 was discovered
Crawl Depth/Click Depth is how deep under the pages SE bots have to go to access the page which signifies the importance attached to a page on our website.
So if a high revenue-generating page with massive search volume potential is buried at a crawl depth of 14; it implies though we know this is an important page for the business, the SE bots infer that this page mustn’t be that important and as a result, the organic visibility and rankings of the page may suffer.
Ideally, crawl depth should not be greater than 5, but 40?
It’s a massive number to look at, and this was definitely a thing we aimed to fix by strengthening the overall internal linking structure.
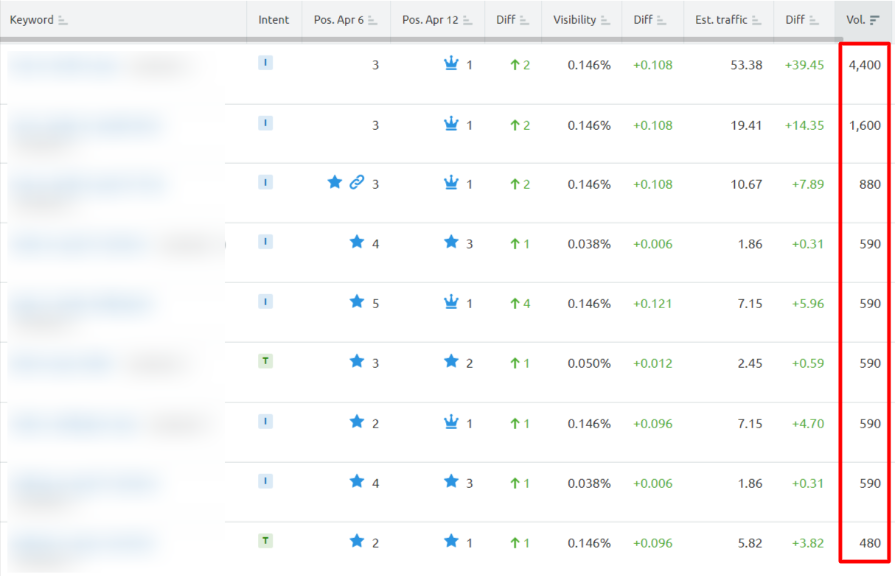
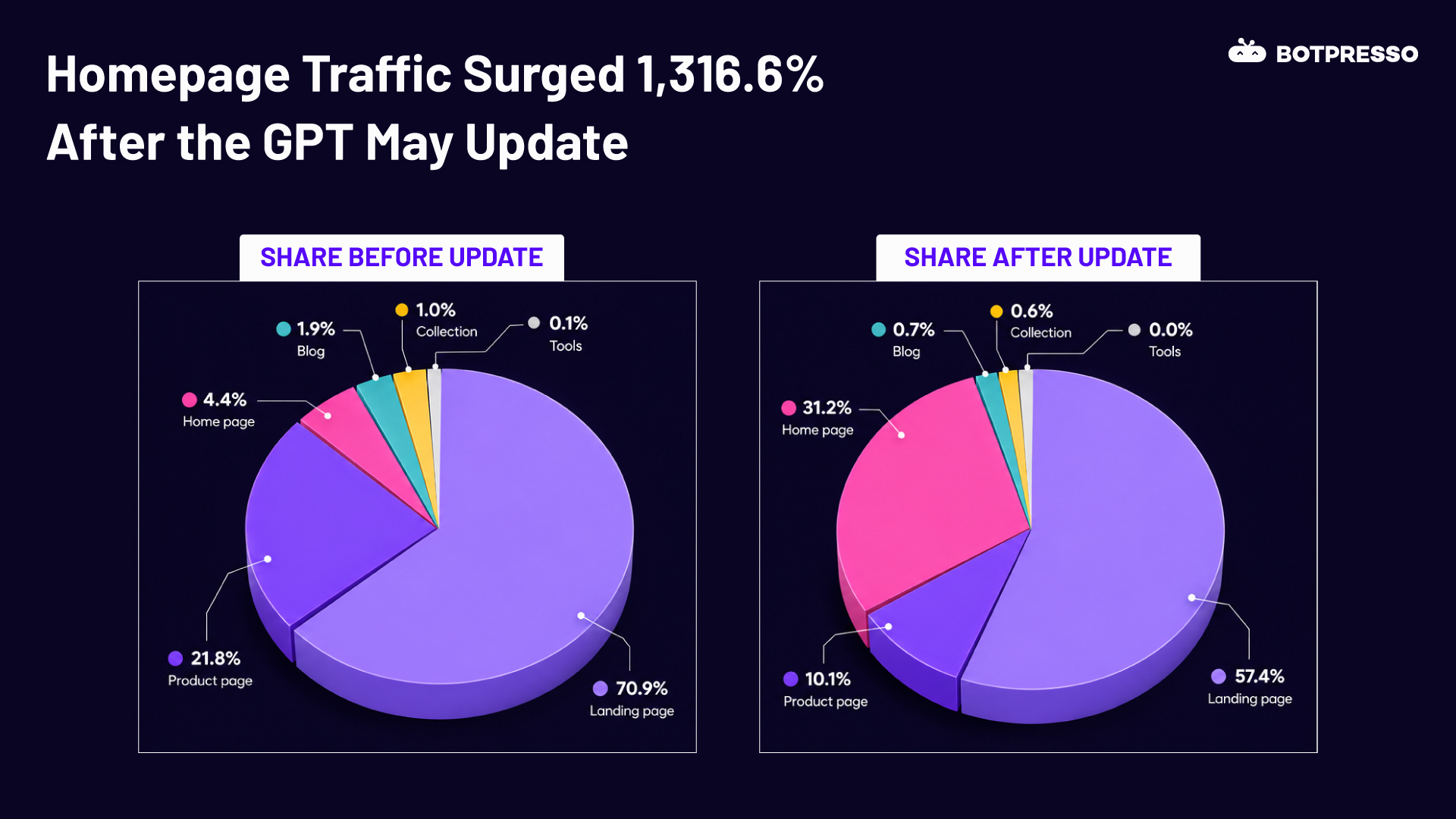
Important keyword cluster tapped into the featured snippet position.
Key Takeaways
- SEO is UXO
- Keep working on improving the bot experience on the website
- Never stop monitoring the HTTP Status codes
- When working on Schema understand the signals sent to Google and find ways to have clear communication with SE bots via Schema code